Selenium 是什么

Selenium 是一个驱动浏览器的自动化工具,开发它的初衷是自动化测试 web 应用。到了爬虫的年代,爬虫工程师把它拿来模拟浏览器,去抓取普通方式获取不到的数据。
Selenium 的优势
- 获取 JavaScript 渲染后的数据。比如:基于 vue.js 开发的前端页面。
- 获取带有验证的 Ajax 请求的数据。有些 API 请求,会构造签名,如果我们不用 Selenium,则需要去了解签名算法。
Selenium 的劣势
- 相比 Requests 库,Selenium 速度慢,占用资源更多
- 容易被识别出来。比如使用 chromedriver,可以通过预定义变量识别。
安装
Selenium 支持的驱动有很多,比如 Google Chrome、Firefox、Internet Explorer 等。这里以使用 Chrome Driver 为例子。
- 下载并安装 Google Chrome 浏览器。
- 下载 chrome driver。
- 将 chrome driver 移动到 PATH 环境变量中。比如 Linux 下的 /usr/local/bin。
- 使用 pip3 安装 Python 库 selenium。
使用
快速入门
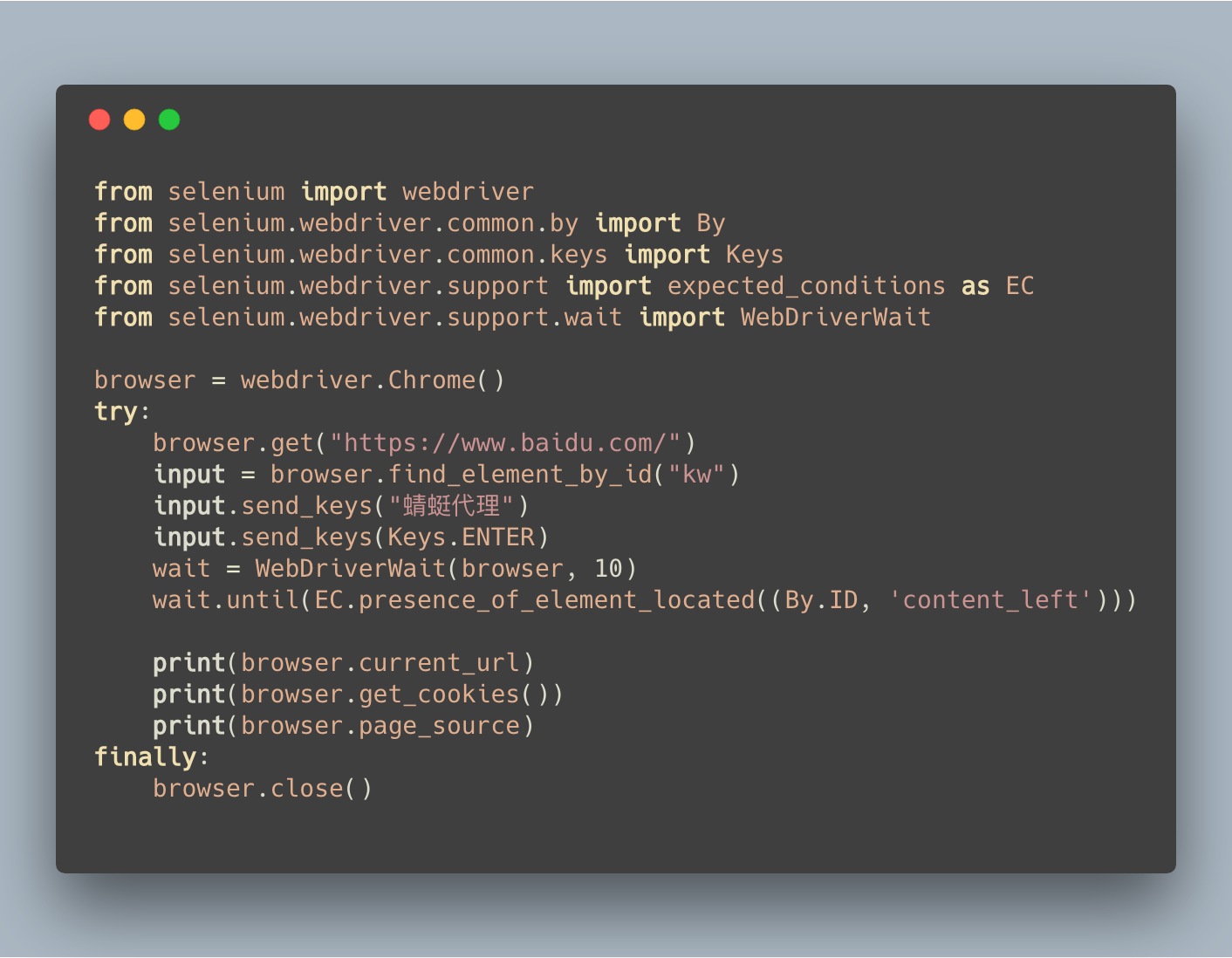
上面的代码,做了下面几件事情:
- 打开浏览器;
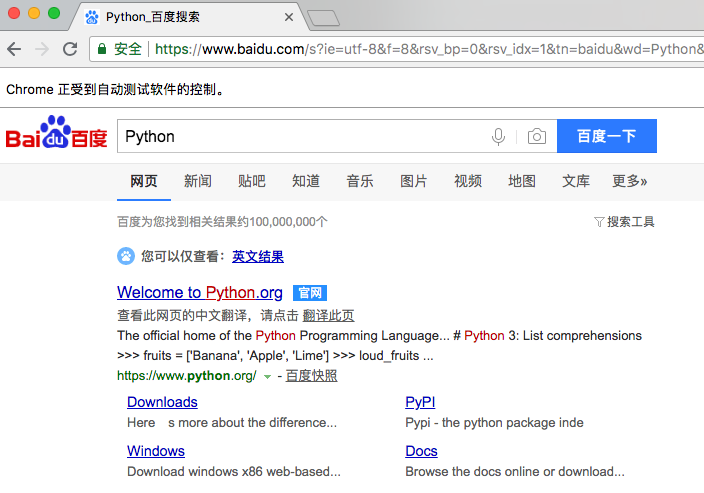
- 打开百度;
- 输入搜索『Python』关键字;
- 点击『百度一下』按钮;
- 等待百度返回搜索结果;
- 获取当前浏览器的 url、cookies 和源码;
相关系列文章
Python3 爬虫教程系列文章接下来会连载下去,大家可以关注蜻蜓代理的博客,第一时间阅读最新文章。
基础篇
转载请注明
- 蜻蜓代理 - Python3爬虫教程基础篇之四:Selenium详解
- 头条号 - 蜻蜓软件
- 微信公众号:蜻蜓软件(qingtingsoft)

