爬虫的定义
爬虫,全名为网络爬虫(英文:web crawler),是一种请求网络资源并提取保存的计算机自动化程序。
最典型的爬虫是百度爬虫。它通过第一时间收集互联网的最新资源并建立索引,使得用户可以在百度(www.baidu.com)中快速地搜索互联网资源。
爬虫的基本流程
1. 发送 HTTP 请求(Request)
通过 Python 库向目标站点发送 HTTP 请求,等待服务器响应。如下图,即是客户端向 example.com 服务器发送的 HTTP 原始请求。
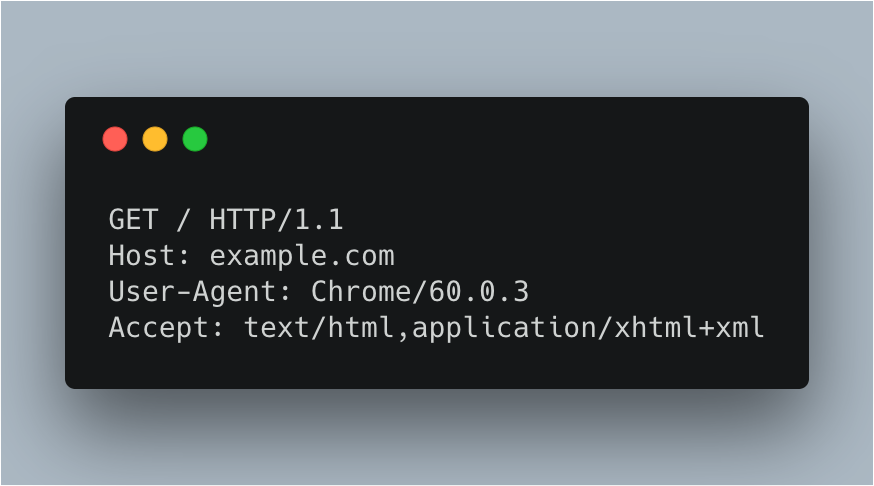
2. 获取响应内容(Response)
接着,如果服务器 example.com 正确理解了上图的请求,就会返回 200 状态码的响应内容。
如下图:
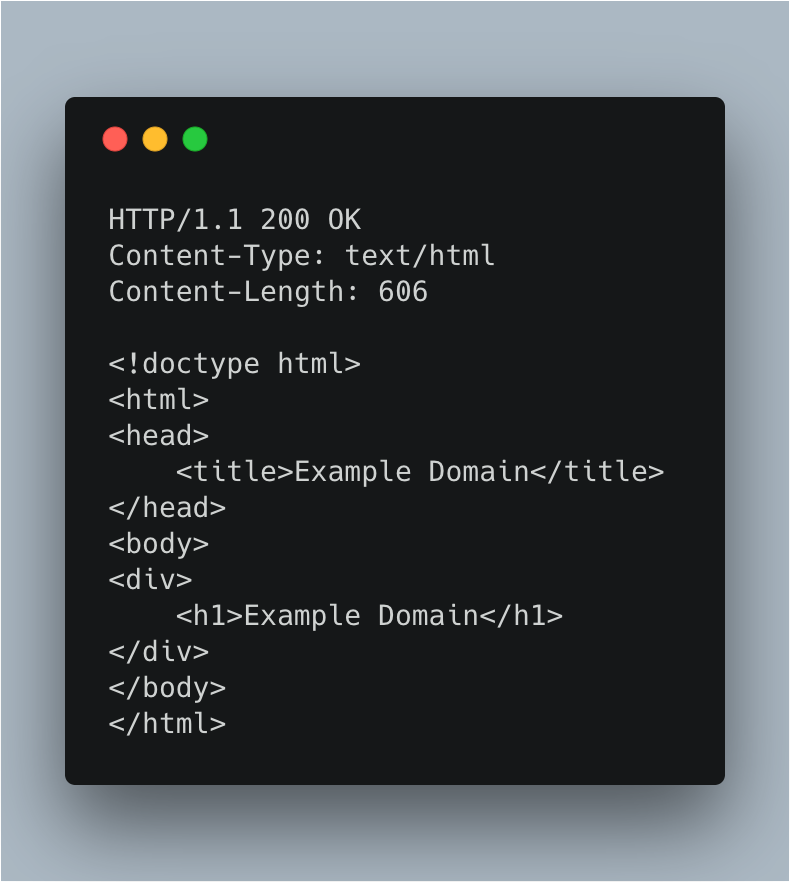
HTTP/ 1. 1 表示使用的是 1. 1 版本的 HTTP 协议。
200 是状态码,后面的 OK 是对状态码的简单描述(status text)。常见的 HTTP 状态码还有301 (资源永久转移)、 404 (未找到资源)、 500 (服务器内部错误)等。
Content‑Type 和 Content‑Length 都是响应结果的头部(header)。分别表示:内容的类型及内容的长度。
隔了一行之后,则是响应头(Response Body)。这里可以明显的看出,这是 HTML 格式的响应结果。
3. 解析结果(Extract)
从上图可知,返回的是 HTML 格式的响应结果。Python 一般使用 Beautiful Soup 或 pyquery 这两个库去解析。之后会讲解它们,这里不具体展开。
4. 进一步处理数据
根据业务需求,对数据进一步处理。比如:数据的清洗、脱敏、分类等。
5. 保存数据
假设响应结果被解析成如下内容:
根据实际情况,保存到文件、非关系型数据库或关系型数据库中。
代码示例
import requests
from pyquery import PyQuery as pq
# 发送 HTTP 请求,并获取响应结果
r = requests.get("http://example.com/")
# 处理异常结果
if r.status_code != 200:
print("request err, status code: " + r.status_code)
exit(-1)
# 解析结果
d = pq(r.text)
title = d("head > title").text()
content = d("body").html()
# 这里仅仅打印,不做其他处理
print(title)
print(content)
转载请注明
- 蜻蜓代理 - Python3爬虫教程基础篇之一:什么是爬虫
- 头条号 - 蜻蜓软件
- 微信公众号:蜻蜓软件(qingtingsoft)

