Requests 是什么
Requests 是 Kenneth Reitz 编写的一个优雅、易用的 HTTP 库。Requests 的底层基于 Python 官方库 urllib,但 Requets 良好的 API 设计更适合人类使用。
Requests 的核心类
Requests 最核心的两个类,一个是 request(对 HTTP 请求的分装),另一个是 response(对 HTTP 返回结果的封装)。
简单来说,一次 HTTP 请求,其实就是:
- 构造 request 类;
- 通过 urllib 发送 HTTP 请求;
- 等待服务器并获取服务器响应结果;
- 解析响应结果,并构造 response 类;
从上面可以看出,理解了 request 和 response 类,对掌握 Requests 库和学习 HTTP 协议有很大的帮助。
request 类
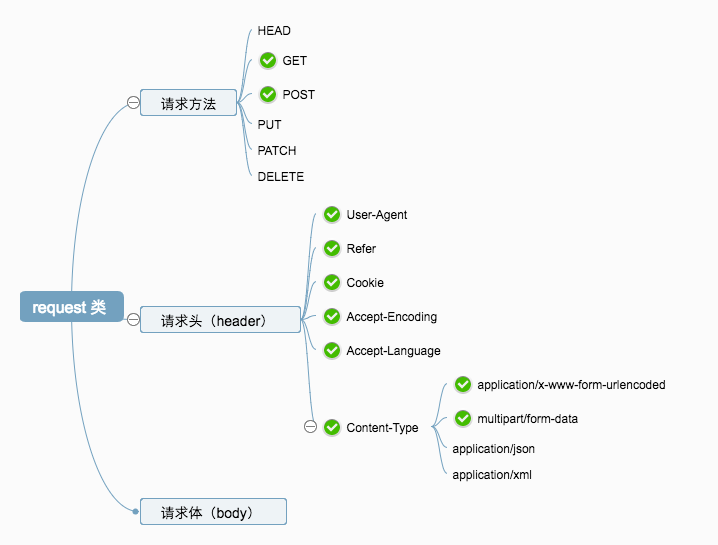
请求方法
用法:请求方法 资源名。比如:GET /help.html、POST /users
常用的请求方法如下:
- GET:常用的请求方法,表示获取资源的意思。比如:
GET /index.html的意思就是,获取index.html这个文件资源。 - HEAD:与
GET方法类似,但是只返回 headers。HEAD 方法通常用于判断一个较大的文件资源是否存在。比如,有一个100M的视频文件,如果用GET方法,则这个请求耗时太长。而如果用HEAD方法,只获取这个资源的 header 信息,则速度会快许多。 - POST:创建资源
- PUT:更新资源
- DELETE:删除指定资源
- PATCH:更新指定资源的部分信息
示例:
- GET /users/joker:获取 /users/joker 这个资源。从人类的角度看,这里的意思是,获取 joker 这个用户的信息。
- POST /users:创建一个用户,用户的信息存储在 body 中,这里没展示出来
- DELETE /users/joker:删除 joker 这个用户
请求头
请求头是 request 和 response 的描述信息。这里列举几个在爬取数据过程中,比较重要的几个 header。如下:
- User-Agent:简称 UA,存储客户端的一些信息。如果是浏览器的 UA,一般会记录浏览器的名称(Chrome/Firefox/IE 等),操作系统(Windows/Linux/macOS 等)。如果是自定义程序,一般规则是:程序名/版本号。比如:python-requests/2.18.3。在爬取数据的过程中,一般都是将 UA 模拟成常用浏览器的 UA,避免被封。
- Referer:记录请求的来源。一般用于防盗链。比如:example.com 的图片,只允许自己网站使用。如果 a.com 使用了 example.com 的图片,则 Referer 默认为:a.com。example.com 看到了 Referer 来源不是自家的,一般就会提示:此图为盗链,请直接访问:example.com。这里建议在爬取数据的过程中,将 Referer 设置为目标站点。
- Cookie:一般用于识别用户身份。在爬取过程中,如果目标网站模拟登陆较难,则可以手动登录后,获取 cookie,然后在程序中使用。
- Content-Type:说明 body 的类型。需要保证该值正确,否则服务器可能无法正常解析请求数据。
请求体
不同的 Content-Type 头部,请求体的格式是不同的,这里不多做说明。
response 类
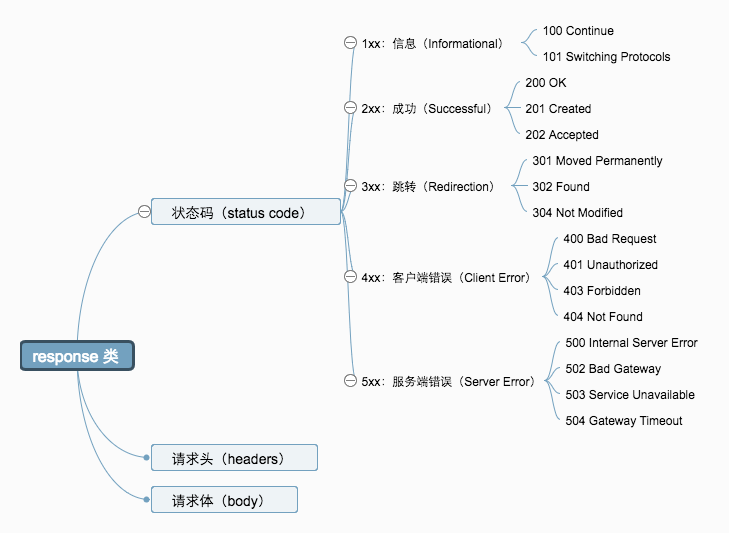
状态码
状态码一共有5大分类,如下:
- 1xx:信息相关,较少使用到。
- 2xx:请求被服务端正确处理,最常见的就是:200 OK
- 3xx:表示重定向,需要客户端从 Location header 中获取新的资源地址
- 4xx:表示客户端发生错误
- 5xx:表示服务端发生错误
转载请注明
- 蜻蜓代理 - Python3爬虫教程基础篇之二:网络库Reqeusts详解(上)
- 头条号 - 蜻蜓软件
- 微信公众号:蜻蜓软件(qingtingsoft)

