PyQuery 简介
PyQuery 用于对 XML 文档进行操作,比如:查询 XML 文档中的某个元素,获取某个元素的属性等。它的 API 和前端著名框架 jQuery 相似,名字的由来也是基于此。(官方介绍:pyquery: a jquery-like library for python)
安装
$ pip3 install pyquery
加载 XML 文档
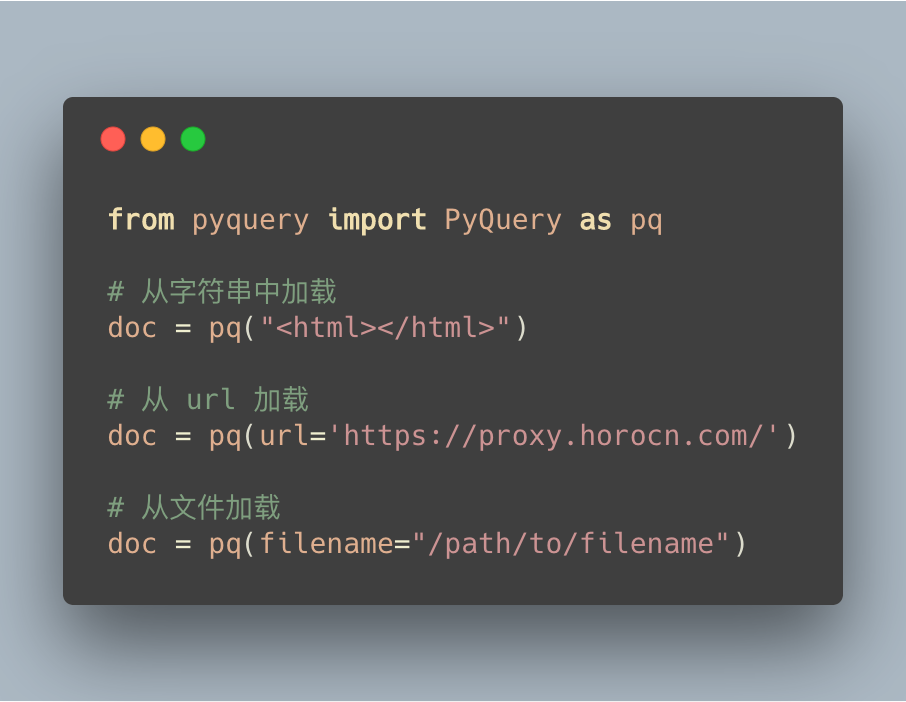
pyquery 提供了三种 XML 加载方式:
- 从字符串中加载;
- 从 url 加载;
- 从文件加载;
这里,我们一般使用 Requests 获取网络资源数据,接着,使用 pyquery 从字符串中加载数据。
这样做的理由是,Requests 作为一个专门的网络库,有较强的定制能力。
简单看下示例代码:
查询元素
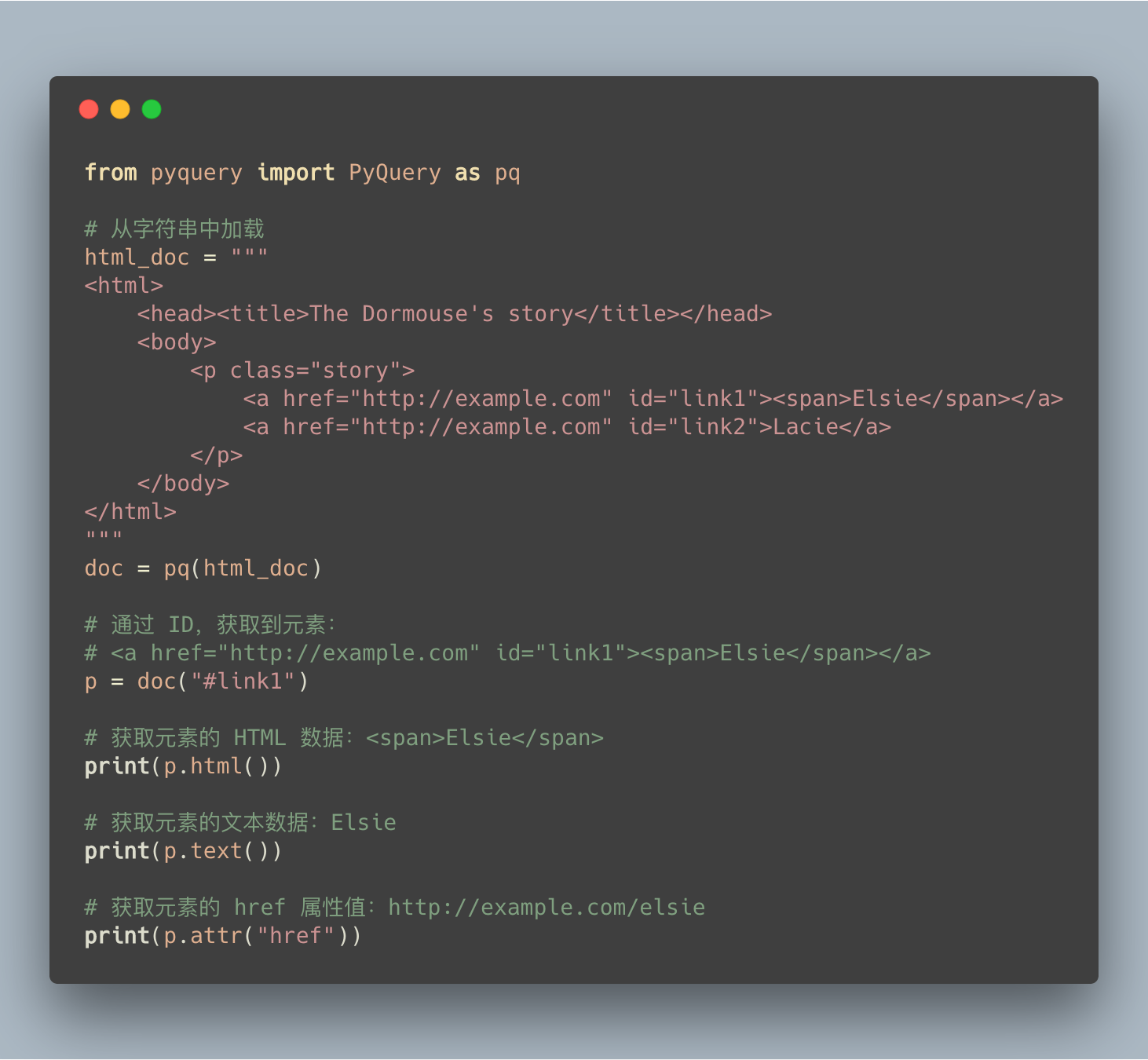
查询元素的核心点是 CSS 选择器(CSS Selector),大家可以通过搜索引擎查找相关资料。
Tip
PyQuery 支持手动选择解析器(parser),如下:
pq('<html><body><p>toto</p></body></html>', parser='xml')
parse 的取值是:
- xml
- html
- html5
- soup
- html_fragments
默认使用的是 lxml 的 xml 解析器,一般不需要手动选择。这里只是作为一个小知识点提及。
相关系列文章
Python3 爬虫教程系列文章接下来会连载下去,大家可以关注头条号第一时间阅读最新文章。
基础篇
转载请注明
- 蜻蜓代理 - Python3爬虫教程基础篇之三:PyQuery详解
- 头条号 - 蜻蜓软件
- 微信公众号:蜻蜓软件(qingtingsoft)

