概述
基础篇讲了爬虫原理以及采集数据过程中常用的库。现在是时候练练手啦。

解析阶段
打开猫眼电影首页 - 榜单 - TOP100榜。

可以看出,采用的是分页的形式。各个页面的 url 如下:
- 第一页:https://maoyan.com/board/4
- 第二页:https://maoyan.com/board/4?offset=10
- 第三页:https://maoyan.com/board/4?offset=20
- 最后一页:https://maoyan.com/board/4?offset=90
从上面可以很容易看出,直接循环生成 offset 即可。
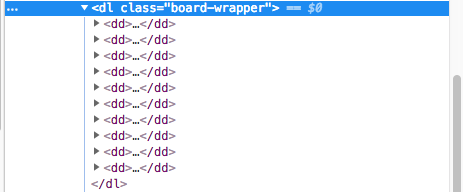
打开谷歌浏览器的开发者工具(F12),分析下 DOM。
可以看出,我们需要的数据在 .board-content dd 下。
开发阶段
解析完成后,开始开发。这里分成三个步骤:
- 使用 Requests 抓取页面数据;
- 使用 PyQuery 解析内容;
- 将结果存储到文件中;
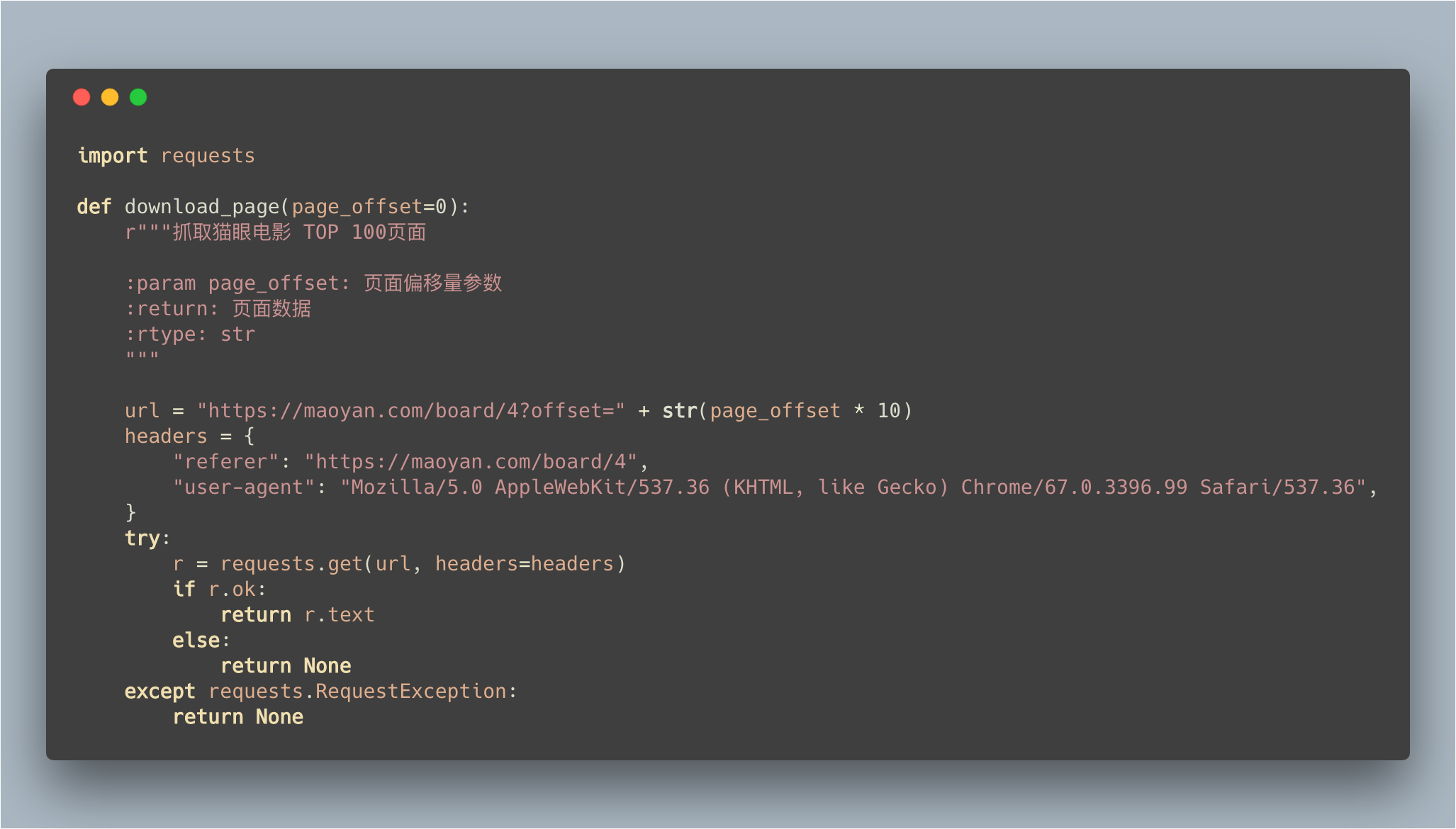
使用 Requests 抓取页面数据
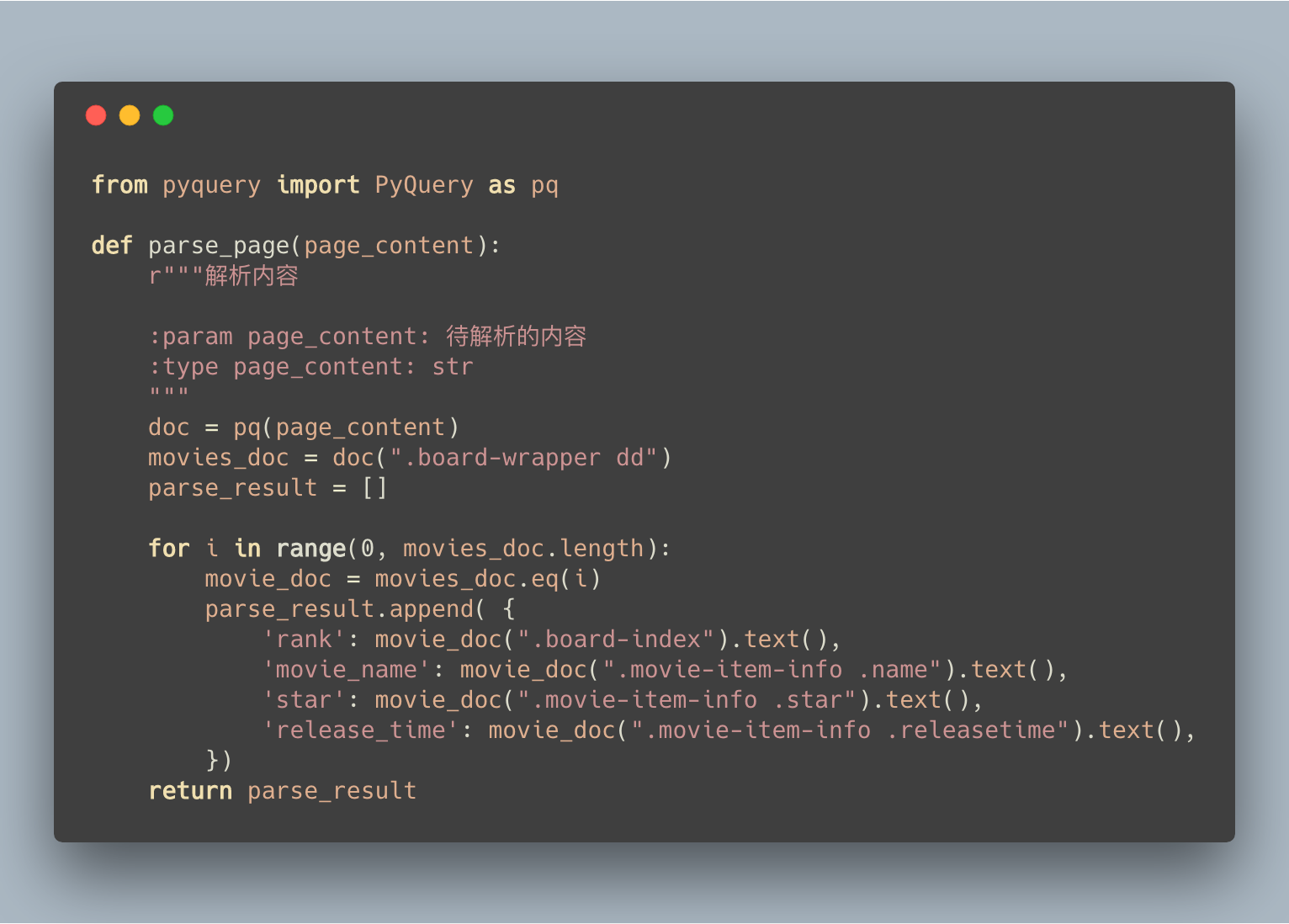
使用 PyQuery 解析内容
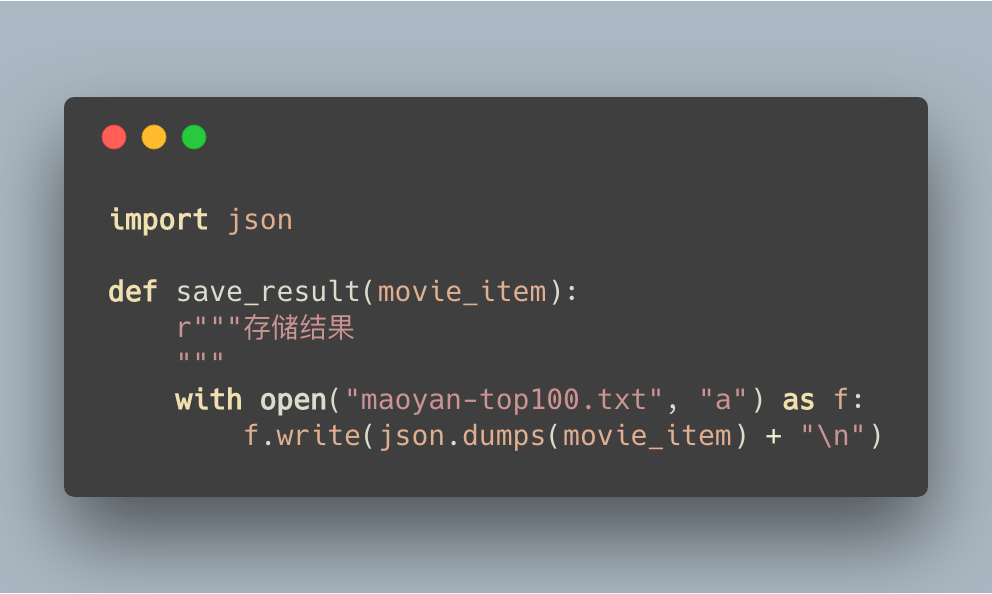
将结果存储到文件中
完整代码
import requests
from pyquery import PyQuery as pq
import json
def download_page(page_offset=0):
r"""抓取猫眼电影 TOP 100页面
:param page_offset: 页面偏移量参数
:return: 页面数据
:rtype: str
"""
url = "https://maoyan.com/board/4?offset=" + str(page_offset * 10)
headers = {
"referer": "https://maoyan.com/board/4",
"user-agent": "Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36",
}
try:
r = requests.get(url, headers=headers)
if r.ok:
return r.text
else:
return None
except requests.RequestException:
return None
def parse_page(page_content):
r"""解析内容
:param page_content: 待解析的内容
:type page_content: str
"""
doc = pq(page_content)
movies_doc = doc(".board-wrapper dd")
parse_result = []
for i in range(0, movies_doc.length):
movie_doc = movies_doc.eq(i)
parse_result.append( {
'rank': movie_doc(".board-index").text(),
'movie_name': movie_doc(".movie-item-info .name").text(),
'star': movie_doc(".movie-item-info .star").text(),
'release_time': movie_doc(".movie-item-info .releasetime").text(),
})
return parse_result
def save_result(movie_item):
r"""存储结果
"""
with open("maoyan-top100.txt", "a") as f:
f.write(json.dumps(movie_item) + "\n")
if __name__ == '__main__':
for offset in range(0, 10):
page_content = download_page(offset)
result = parse_page(page_content)
for movie_item in result:
save_result(movie_item)
转载请注明
- 蜻蜓代理 - Python3爬虫教程实战篇之一:抓取猫眼电影TOP100电影
- 头条号 - 蜻蜓软件
- 微信公众号:蜻蜓软件(qingtingsoft)

